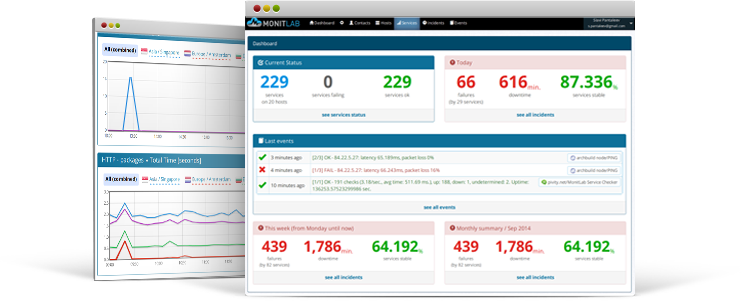
Simple and reliable website and server monitoring.
-
 Systems fail (sooner or later)
Systems fail (sooner or later)
-
 We check from multiple locations around the world
We check from multiple locations around the world
-
 We tell you as soon as (or before) failures happen
We tell you as soon as (or before) failures happen
-
 You fix problems early, your customers love you
You fix problems early, your customers love you
HOW IT WORKS?
We'll alert you when your site is down via email or SMS.
NO FALSE-POSITIVES!

CHECKING 24/7 FROM ALL OVER THE WORLD!





MONITORING FROM ALL OVER THE WORLD
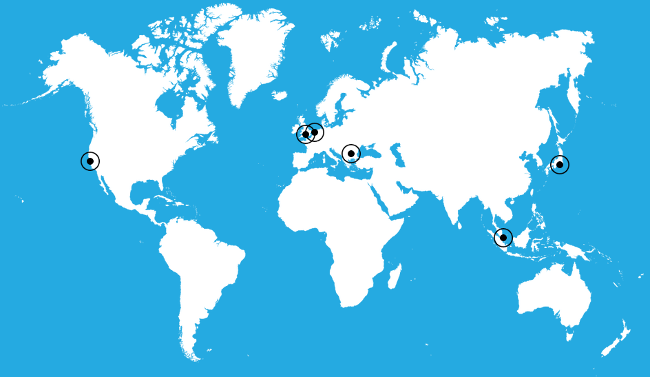

Global
We monitor all your services non-stop from 3 different continents. Get a global look on things. We never miss a failure!

Notifications
Sleep tight and relax. We'll let you know when things fail. Before an angry customer does! According to your schedule, of course.

Graphs
We don't just do checks. We also collect metrics and draw graphs. Use them to find patterns and see the trends.

Reports
How many failures did you have? Was this month better than last? See what the bottom line is and strive for improvement.
OUR SERVICE TYPES
Basic
$
7
/mo
$
5
/mo
Paid annually, 29% off
Checks:
10
Servers:
1
Notifications contacts:
2
Check Locations:
1
Signup SMS Credits:
30
Data history days:
7
Multi-user login:
Standard
$
30
/mo
$
20
/mo
Paid annually, 33% off
Checks:
60
Servers:
5
Notifications contacts:
6
Check Locations:
3
Signup SMS Credits:
200
Data history days:
30
Multi-user login:
(up to 3 user accounts)
Standard+
$
56
/mo
$
40
/mo
Paid annually, 29% off
Checks:
150
Servers:
10
Notifications contacts:
10
Check Locations:
3
Signup SMS Credits:
200
Data history days:
30
Multi-user login:
(up to 5 user accounts)
Professional
$
112
/mo
$
80
/mo
Paid annually, 29% off
Checks:
350
Servers:
20
Notifications contacts:
20
Check Locations:
5
Signup SMS Credits:
500
Data history days:
60
Multi-user login:
(up to 20 user accounts)